ARX 소개
최근 IT업계의 트랜드 중에는 빅데이터 사업과 MyData(마이데이터) 관련 사업이 트랜드가 되고 있습니다.
수 많은 IT 업체들이 해당 솔루션을 출시하고, 개발하기 위해 많은 투자를 진행하고 있습니다. 저희 위썸에서도 빅데이터와 마이테이터 관련 사업을 위해 많은 투자를 하고 있습니다. 이와 관련하여 빅데이터와 마이데이터 사업을 위해 꼭 필요한 것으로 개인정보 비식별 조치가 위 사업을 함에 있어 중요한 요소가 되고 있습니다.
개인정보 비식별이 중요한 이유
- 정부 3.0 및 빅데이터 활용 확산에 따른 데이터 활용가치 증대
공공정보 개방·공유는 투명하고 효율적인 정부 운영에, 빅데이터 활용은 과학적 정책 집행 및 맞춤형 서비스 제공에 필수적인 수단
특히, 빅데이터 분석, IoT 기술 등을 통한 새로운 서비스 창출과 신산업 활성화에 데이터의 활용가치 증대
- 개인정보 보호 강화에 대한 사회적 요구 지속
크고 작은 개인정보 유출 사고가 지속되어 개인정보 보호 정책을 강화해야 한다는 사회적 요구가 계속
다양한 데이터 활용을 필요로 하는 새로운 산업과 기술 발전으로 개인정보 침해 위험도 증가 추세
- ‘보호와 활용’을 동시에 모색하는 세계적 정책변화에 적극 대응
- 미국·영국 등 주요 선진국은 개인정보 침해가능성을 최소화하면서 데이터 산업 활성화를 위한 정책 추진 중
- 사생활 침해 방지를 위한 안전장치 마련과 동시에 비식별 조치된 정보는 산업적으로 활용할 수 있도록 구체적인 가이드 제시 필요
by 한국인터넷진흥원 발췌
우리 위썸(wesome)에서는 개인 정보 보호 솔루션 중 가장 많이 사용되는 ARX에 대해 소개해 보자 합니다.
솔루션 문의는 아래 주소로 연락 주십시요.

ARX - Data Anonymization Tool
ARX는 민감한 개인 데이터를 익명화하기 위한 포괄적인 오픈소스 소프트웨어입니다.
다양한 프라이버시 및 위험 모델, 데이터 변환 방법 및 출력 데이터의 유용성을 분석하는 방법을 지원합니다.
이 소프트웨어는 상업용 빅 데이터 분석 플랫폼, 연구 프로젝트, 임상 시험 데이터 공유 및 교육 목적을 포함한 다양한 환경에서 사용되고 있습니다.
이 문서는 ARX 툴에서 사용하는 문서를 번역한 것으로 ARX를 사용한 비식별화에 대한 내용을 보다 이해 하기 위해 제작하였습니다.
보다 정확한 내용은 ARX 사이트를 참고하시길 바랍니다.
Overview
지원되는 익명화 방법 개요
ARX는 다음 개인 정보 보호 모델에 임의의 조합을 지원합니다.
- k-익명성(k-anonymity), l-다양성(l-diversity), t-근접성(t-closeness), δ-공개 프라이버시(δ-disclosure privacy), β-유사성(β-likeness) 및 δ-존재(δ-presence)와 같은 구문 프라이버시 모델.
- k-map과 같은 통계적 프라이버시 모델, 평균 위험에 대한 임계 값 및 슈퍼 인구(super-population) 모델에 기반한 방법.
- (ε, δ)-차등 프라이버시 및 게임 이론적 비식별화 접근과 같은 시맨틱 프라이버시 모델.
ARX는 다음 데이터 변환 모델에 임의 조합을 지원합니다.
- 전역 및 로컬 변환 체계(Global and local transformation schemes) : ARX는 데이터 집합의 모든 레코드에 동일한 변환 체계를 적용하거나 다른 레코드 하위 집합에 다른 변환 체계를 적용 할 수 있습니다.
- 무작위 샘플링(Random sampling) : 입력 데이터 세트에서 무작위 샘플을 추출하여 프라이버시 위험을 줄일 수 있습니다.
- 일반화(Generalization) : 사용자 지정 계층을 기반으로 속성 값을 일반화하여 레코드를 덜 고유하게 만들 수 있습니다.
- 레코드, 속성 및 셀 억제(Record, attribute and cell suppression) : 개별 속성 값을 제거하거나 전체 레코드를 제거하여 프라이버시 위험을 낮출 수 있습니다.
- 마이크로 집계(Microaggregation) : 숫자 속성 값의 클러스터는 사용자 지정 집계 함수를 통해 공통 값으로 결합 될 수 있습니다.
- 상단 및 하단 코딩(Top- and bottom-coding) : 사용자 정의 범위를 초과하는 값은 제거할 수 있습니다.
- 분류(Categorization) : 연속 변수를 자동으로 분류 할 수 있습니다.
지원되는 데이터 품질 모델 및 목적 함수는 다음과 같습니다.
- 데이터 단위 및 변환 정도를 측정하는 셀 지향 모델(Cell-oriented models).
- 가치 분포의 편차를 정량화하는 속성 지향 모델(Attribute-oriented models).
- 엔트로피를 기반으로하는 레코드의 고유성 및 모호성의 정도를 정량화하는 레코드 지향 범용 모델(Record-oriented general-purpose models).
- 워크로드 인식 모델(Workload-aware models), 분류 모델 구축을위한 학습 세트로서 데이터 게시자의 이점 및 출력 데이터의 적합성을 측정합니다.
또한, (1) 데이터 변환 규칙 생성, (2) 데이터 유틸리티 분석, (3) 잔여 재식별 위험 추정, (4) 변환해야 할 유사 식별 변수 찾기 및 (5) 반복적으로 수행하는 방법이 제공됩니다. 반자동 프로세스를 사용하여 익명화 매개 변수를 조정합니다.
Privacy models (프라이버시 모델)
지원되는 개인 정보 보호 모델
데이터를 익명화할 때 일반적으로 세 가지 유형의 개인 정보 위협이 고려됩니다.
- 멤버십 공개(Membership)는 데이터 연결을 통해 공격자가 개인에 대한 데이터가 데이터 세트에 포함되어 있는지를 결정할 수 있음을 의미합니다. 이것이 데이터 세트 자체의 정보를 직접 공개하지는 않지만, 공격자가 메타 정보를 유추 할 수 있습니다. 이것은 암시적 민감한 속성 (데이터 세트에 포함되지 않은 개인의 속성을 의미)을 다루지만 다른 공개 모델은 명시적 민감한 속성을 다룹니다.
- 속성 공개(Attribute disclosure)는 개인을 데이터 세트의 특정 항목에 연결하지 않고도 달성 할 수 있습니다. 개인이 연결하지 않으려는 데이터 세트의 속성인 민감한 속성을 보호합니다. 따라서 공격자에게 관심이 있을 수 있으며 공개될 경우 데이터 주체에게 해를 끼칠 수 있습니다. 예를 들어 데이터 항목 집합에 연결하면 모든 항목이 특정 중요한 속성값을 공유하는 경우 정보를 추론 할 수 있습니다.
- 신원 공개(Identity disclosure) (또는 재식별)는 개인이 특정 데이터 항목에 연결될 수 있음을 의미합니다. 이는 전 세계의 많은 법률과 규정에 따라 데이터 소유자에게 법적 결과를 초래하기 때문에 심각한 유형의 공격입니다. 정의에서 공격자는 개인에 대한 데이터 항목에 포함된 모든 민감한 정보를 학습 할 수 있습니다.
데이터 세트가 보호되어야 하는 공개 위험의 세부 사항은 입력 데이터 세트의 속성을 여러 유형으로 분류하여 지정할 수 있습니다.
- 속성 식별(Identifying) 은 재식별 위험이 높습니다. 데이터 세트에서 제거됩니다. 전형적인 예는 이름 또는 사회보장 번호, 한국으로 치면 주민등록번호 입니다.
- 유사 식별 속성(Quasi-identifying) 을 조합하여 재식별 공격에 사용할 수 있습니다. 그들은 변형 될 것입니다. 일반적인 예는 성별, 생년월일 및 우편 번호입니다.
- 민감한 속성(Sensitive) 은 개인이 연결하지 않으려는 속성을 인코딩합니다. 따라서 공격자에게 관심이있을 수 있으며 공개 될 경우 데이터 주체에게 해를 끼칠 수 있습니다. 수정되지 않은 상태로 유지되지만 t-근접성 또는 l-다양성과 같은 추가 제약이 적용될 수 있습니다. 일반적인 예는 진단입니다.
- 민감하지 않은 속성(Insensitive) 은 개인 정보 위험과 관련이 없습니다. 수정되지 않은 상태로 유지됩니다.
또한 ARX에서 지원하는 일부 개인 정보 보호 및 위험 모델은 특정 공격자 모델을 다룹니다.
- 검찰(prosecutor) 모델에서 공격자의 목표는 특정 개인과는 개인이 데이터 세트에 포함에 대해 그녀는 이미 데이터를 알고 있다고 가정합니다.
- 기자(journalist) 모델에서 공격자는 특정 개인을 대상으로하지만 그녀가 멤버쉽에 대한 배경 지식을 가지고 것으로는 예상되지 않습니다.
- 마케터(marketer) 모델에서 공격자는 특정 개인을 목표로 하지 않지만 그녀는 많은 개인을 다시 식별하는 것을 목표로 합니다. 따라서 공격은 레코드의 더 큰 부분을 재식별할 수 있는 경우에만 성공한 것으로 간주할 수 있다.
ARX는 다른 공격자 모델에 초점을 맞추거나 특정 데이터 유형의 속성에 최적화된 개인 정보 보호 모델 및 대부분의 다양한 모델의 임의 조합을 지원합니다.
k-Anonymity (k-익명성)
이 잘 알려진 개인 정보 보호 모델은 검사 모델에서 데이터 세트가 재식별되지 않도록 보호하는 것을 목표로 합니다. 각 레코드가 유사 식별자와 관련하여 적어도 k-1 개의 다른 레코드와 구별 될 수 없는 경우 데이터 세트는 k-익명 입니다. 구별 할 수 없는 레코드의 각 그룹은 소위 등가 클래스를 형성합니다.
k-Map (k-맵)
이 개인 정보 보호 모델은 k-익명성과 관련이 있지만, 위험은 기본 인구에 대한 정보를 기반으로 계산됩니다. ARX는 통계적 빈도 추정기를 기반으로 하는 두 가지 변형뿐만 아니라 사용자 지정 모집단 테이블을 활용하는 변형을 지원합니다.
Average risk (평균 위험)
이 개인 정보 보호 모델은 레코드의 평균 재식별 위험에 대한 임계 값을 적용하여 마케팅 담당자 모델에서 데이터 세트가 재식별되지 않도록 보호하는 데 사용할 수 있습니다. 모델을 k-익명성과 결합하여 엄격한 평균 위험이라는 개인 정보 보호 모델을 구성 할 수 있습니다. ARX는 k로 정의된 위험 임계 값을 초과하는 일부 레코드를 허용하는 변형도 지원합니다.
Population uniqueness (인구 고유성)
이 개인 정보 보호 모델은 기본 모집단 내에서 고유 한 레코드 비율에 임계 값을 적용하여 마케터 모델에서 데이터 세트가 재식별되지 않도록 보호하는 것을 목표로 합니다. 이를 위해 인구에 대한 기본 정보를 지정해야 합니다. 이 데이터를 기반으로 통계적 슈퍼 모집단 모델은 표본 특성으로 모수화 된 확률 분포로 전체 모집단의 특성을 추정하는 데 사용됩니다. ARX는 Hoshino (Pitman), Zayatz 및 Chen 및 McNulty (SNB)의 방법을 지원합니다. 다른 모델은 모집단 고유 수에 대해 다르게 정확한 추정치를 반환 할 수 있습니다. 일반적으로 Pitman 모델은 10% 이하의 분수를 샘플링하는 데 사용해야 합니다. ARX는 또한 Dankar 등이 임상 데이터 세트에 대해 제안하고 검증한 결정 규칙을 구현합니다.
참고 : 모집단 고유성을 추정하는 방법은 데이터 세트가 모집단의 균일한 표본이라고 가정합니다. 그렇지 않은 경우 결과가 정확하지 않을 수 있습니다.
Sample uniqueness (샘플 고유성)
이 프라이버시 모델은 유사 식별자와 관련하여 고유 한 레코드의 비율을 제한하는 데 사용할 수 있습니다.
ℓ-Diversity (ℓ-다양성)
이 개인 정보 보호 모델을 사용하여 각 중요 속성이 각 동등성 클래스에서 ℓ 이상의 “잘 표현된” 값을 갖도록 하여 속성 노출로부터 데이터를 보호할 수 있습니다. 서로 다른 다양성 척도를 구현하는 다양한 변종이 제안되었으며, 소프트웨어에 의해 두 개의 서로 다른 추정자(Shannon 또는 Grassberger)와의 구별되는 다양성, 재귀성(c, rop)-다양성, 엔트로피-다양성(Entropy-diversity)이 지원됩니다.
t-Closeness (t-근접성)
이 개인 정보 모델을 사용하여 속성이 노출되지 않도록 데이터를 보호할 수 있습니다. 각 동등성 클래스 내의 민감 속성 값 분포는 입력 데이터 집합의 속성 값 분포에 대해 t 이하의 거리를 가져야 합니다. 이를 위해, 이 값은 지구 이동자의 거리(EMD)를 사용하여 계산되는 주파수 분포 간의 누적 절대적 차이를 제한합니다. 데이터 유형이 다른 변수에 대해 다양한 변형이 제안되었습니다. (1) 동일한 지면 거리는 모든 값이 서로 동등하게 거리를 두는 것으로 간주합니다. (2) 계층적 접지 거리는 값 일반화 계층 구조를 사용하여 값 사이의 거리를 결정하고 (3) 순서가 지정된 지면 거리는 값 순서를 기준으로 거리를 계산합니다.
δ-Disclosure privacy (δ- 공개 프라이버시)
이 개인 정보 보호 모델은 속성 공개로부터 데이터를 보호하는데도 사용할 수 있습니다. 또한 민감한 값의 분포 사이의 거리에 제한을 적용하지만 t-근접성이 사용하는 정의보다 더 엄격한 곱셈 정의를 사용합니다.
β-Likeness (β-유사성)
이 프라이버시 모델은 t-closeness 및 δ-disclosure 프라이버시와 관련이 있으며 속성 공개로부터 데이터를 보호하는 데에도 사용할 수 있습니다. 긍정 및 부정 정보 이득을 고려하여 민감한 속성 값 분포 간의 상대적 최대 거리를 제한하여 이전 모델의 한계를 극복하는 것을 목표로합니다.
δ-Presence (δ-존재)
이 모델은 멤버십 공개로부터 데이터를 보호하는 데 사용할 수 있습니다. 모집단의 개인이 데이터 세트에 포함될 확률이 $δ min$ 과 $δ max$ 사이에있는 경우 데이터 세트는 $(δ min , δ max )$-존재합니다 . 이러한 확률을 계산할 수 있으려면 사용자가 모집단 테이블을 지정해야합니다.
Profitability (수익성)
이 모델은 데이터 게시의 비용 / 이익 분석을 수행하는 게임 이론적 접근 방식을 구현하여 데이터 게시자의 금전적 이익을 극대화하는 출력 데이터 세트를 만듭니다.
Differential privacy (차별적 프라이버시)
이 모델에서 개인 정보 보호는 데이터 세트의 속성이 아니라 데이터 처리 방법의 속성으로 간주됩니다. 비공식적으로 익명화 프로세스의 출력 가능성이 개인의 데이터가 입력 데이터에 추가되거나 제거되는 경우 “별로”변하지 않음을 보장합니다. 결과적으로 공격자가 특정 개인에 대한 정보를 도출하기가 매우 어려워지고 데이터 세트는 멤버십, 신원 및 속성 공개로부터 보호됩니다. 차동 프라이버시는 공격자의 배경 지식 (예 : 연결에 사용할 수있는 속성)에 대해 강력한 가정을 더하지 않습니다. 대신 모든 속성이 유사 식별이되도록 정의해야합니다.
Data quality models (데이터 품질 모델)
지원되는 품질 / 유틸리티 모델
데이터 품질 측정은 복잡한 문제이며 ARX는 익명화 프로세스의 출력 데이터를 최적화하기 위한 목적 함수로 사용할 수 있는 여러 모델을 지원합니다. 일반적으로 이러한 방법은 데이터 품질 저하를 정보 손실의 증가로 모델링하며 이는 정량화 할 수 있습니다. ARX는 개별 셀 값, 속성 또는 레코드를 기반으로 품질을 측정하는 품질 모델과 분류 모델 생성에 초점을 맞춘 워크로드 인식 모델을 지원합니다.
셀 지향 및 속성 지향 모델은 개별 측정값이 전체 데이터 세트에 대한 전역 측정값으로 컴파일되는 방법을 정의하는 여러 집계 함수로 매개 변수화될 수 있습니다. 다음 집계 함수를 사용할 수 있습니다.
- 순위(Rank) : 사전 순으로 비교되는 모든 속성에 대한 정렬 된 측정 목록입니다.
- 기하 평균(Geometric mean) : 모든 속성에 대한 측정의 기하 평균입니다.
- 산술 평균(Arithmetic mean) : 모든 속성에 대한 측정의 산술 평균입니다.
- 합계(Sum) : 모든 속성에 대한 측정의 합계
- 최대(Maximum) : 모든 속성에 대한 최대 측정 값
셀 지향 및 속성 지향 측정 값은 추가 분석을위한 속성의 중요성을 지정하는 속성 가중치로 추가 매개 변수화 할 수 있습니다. ARX는 중요도가 높은 속성에 적용되는 변형 정도를 줄이기 위해 노력할 것입니다.
Cell-oriented general-purpose models (셀 지향 범용 모델)
- 세분성 / 손실(Granularity/loss) :이 측정은 변환 된 속성 값이 속성의 원래 도메인을 포함하는 정도를 요약합니다. ARX는 일반화 규칙의 기능적 표현을 기반으로이 범위를 정량화하는 정교한 방법을 구현합니다. 또한 모델을 매개 변수화하여 데이터 세트에 적용될 일반화 및 억제 정도에 영향을 줄 수 있습니다.
- 정밀도(Precision) :이 모델은 변환 된 속성 값의 정규화 된 일반화 수준을 기반으로 데이터 품질을 추정합니다.
Attribute-oriented general-purpose models (속성 지향 범용 모델)
- 비 균일 엔트로피(Non-uniform entropy) :이 모델은 출력 데이터 세트의 변수 값을 관찰하여 입력 데이터 세트에서 변수의 원래 값에 대해 얻을 수있는 정보의 양을 측정하는 상호 정보를 기반으로 정보 손실을 정량화합니다.
- 높이(Height) :이 매우 간단한 모델은 모든 속성 값에 적용된 일반화 수준의 합계로 정보 손실을 수량화합니다.
Record-oriented general-purpose models (기록 지향 범용 모델)
- 평균 등가 클래스 크기(Average equivalence class size) :이 모델은 구별 할 수없는 레코드 클래스의 평균 크기를 계산하여 데이터 품질을 추정합니다. 출력 데이터 세트의 실제 속성 값은 고려하지 않습니다.
- 식별성(Discernibility) :이 모델은 또한 출력 데이터 세트의 등가 클래스 크기를 기반으로 데이터 품질을 추정합니다. 억제 된 기록은 불이익을받습니다. 출력 데이터 세트의 실제 속성 값은 고려하지 않습니다.
- 모호성(Ambiguity) :이 모델은 출력 데이터 세트의 레코드가 모호한 정도를 정량화합니다.
- 엔트로피 기반 모델(Entropy-based model) :이 모델은 여기 에서 제안 되었습니다 .
Special-purpose models (특수 목적 모델)
ARX는 또한 수익성 개인 정보 보호 모델에 구현 된 게임 이론적 접근 방식에 따라 데이터 게시자의 이익을 극대화하기위한 모델을 구현합니다.
Transformation models (변환 모델)
지원되는 변환 방법
ARX는 서로 결합 할 수있는 다양한 공통 데이터 변환 모델을 지원합니다.
Global and local transformation schemes (글로벌 및 로컬 변환 계획)
ARX는 데이터 집합의 모든 레코드에 동일한 변환 체계를 적용하거나 레코드의 다른 하위 집합에 서로 다른 변환 체계를 적용하도록 구성할 수 있습니다. 사용할 수 있는 최대 변환 수를 지정할 수 있습니다. 결과 데이터 변환 계획의 정확한 속성은 사용자가 설정한 추가 매개 변수에 따라 달라집니다. 예를 들어 값 일반화 계층이 지정된 경우 전역 변환을 수행하면 특성 도메인의 각 값이 동일한 일반화 수준으로 변환되는 전체 도메인 일반화가 발생합니다. 로컬 변환의 경우 서로 다른 레코드의 동일한 속성 값에 서로 다른 일반화 수준을 사용할 수 있습니다. 마찬가지로 값만 표시하도록 변환 규칙이 지정된 경우 전역 변환 프로세스에서는 특성이 억제되는 반면 로컬 변환 프로세스에서는 셀 억제 체계가 생성됩니다.
Value generalization (가치 일반화)
사용자 지정 일반화 계층은 ARX 데이터 변환 메커니즘의 중추를 형성합니다. 계층을 사용하여 속성 값의 고유성을 직접 줄이거 나 마이크로 집계와 같은 추가 방법을 사용하여 변환 될 클러스터를 형성 할 수 있습니다.
Random sampling (무작위 샘플링)
ARX는 입력 데이터 집합에서 샘플을 그리는 여러 가지 방법을 지원합니다. 이를 통해 데이터 집합을 기본 모집단 테이블과 연관시키거나 개인 정보 보호 위험을 줄일 수 있습니다. 랜덤 샘플링은 ARX에서 지원하는 차동 개인 정보 메커니즘에 랜덤성을 도입하는 데 추가로 사용됩니다.
Record, attribute and cell suppression (기록, 속성 및 세포 억제)
앞서 설명한 것처럼 ARX는 변환 프로세스에서 개별 속성, 속성 값 또는 전체 레코드 제거도 지원합니다. 이는 적절한 계층 (특정 마법사에서 지원)을 정의하고 로컬 또는 글로벌 변환을 수행하고 제거 할 수있는 최대 레코드 수에 대한 제한을 지정하여 제어 할 수 있습니다.
Microaggregation (미세 응집)
숫자 속성 값 집합을 사용자 지정 집계 함수에 의해 공통 값으로 변환할 수 있습니다. 집계하기 전에 가치 일반화 계층을 기반으로 클러스터링을 수행할 수 있습니다.
Top- and bottom-coding (상단 및 하단 코딩)
ARX의 기본 제공 마법사를 사용하여 적절한 계층을 구성함으로써 사용자 지정 범위를 초과하는 값을 자르는 계층을 만들 수 있습니다.
Categorization (분류)
소프트웨어에서 제공하는 마법사를 사용하여 함수로 표시되는 변환 규칙을 생성 할 수 있으며, 익명화 중에 연속 변수의 즉석 분류를 수행하는 데 사용할 수 있습니다.
Anonymization tool
ARX의 관점 개요
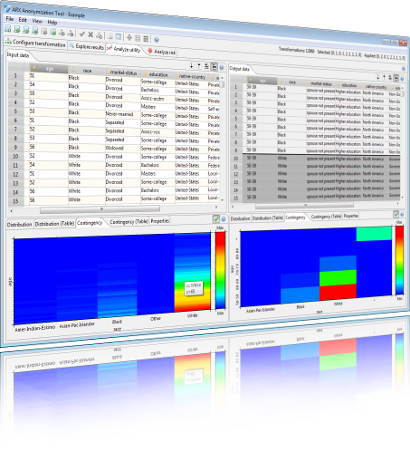
ARX는 익명화 프로세스의 다양한 측면을 모델링하는 네 가지 관점으로 나뉩니다. 아래에서 볼 수 있듯이 이러한 관점은 1) 프라이버시 모델, 유틸리티 측정 및 변환 방법 구성, 2) 솔루션 공간 탐색, 3) 데이터 유틸리티 분석 및 4) 프라이버시 위험 분석을 지원합니다.
구성(configuration) 관점에서 입력 데이터를 로드하고 변환 규칙을 지정할 수 있으며 개인 정보 모델 및 유틸리티 측정과 같은 추가 매개 변수를 모두 선택하고 매개 변수를 지정할 수 있습니다. 필요한 경우 리스크 분석을 수행하여 이 단계를 준비할 수 있습니다.
익명화(anonymization) 프로세스가 끝나면 탐색적(exploration) 관점에서 잠재적 솔루션에 대한 개요를 검사할 수 있습니다. 여기서 개인 정보 보호 데이터 변환을 검색할 수 있으며, 따라서 의도된 사용 시나리오에 적합한 출력 데이터가 생성됩니다. ARX는 자동으로 솔루션을 제안합니다.
출력 데이터의 유용성을 평가하기 위해, 효용 분석 관점은 정보 손실 모델, 기술 통계 및 응용 프로그램별 분석(예: 기계 학습 과제에 집중)을 사용하여 변환된 데이터를 입력 데이터와 비교하는 방법을 제공합니다.
네 번째 관점에서는 변환된 출력 데이터뿐만 아니라 입력 데이터셋에 대한 개인 정보 보호 위험을 분석할 수 있습니다. 이러한 분석 결과에 따라 솔루션 후보 적합성이 확인되거나 익명화 프로세스의 매개 변수가 수정되어 반자동화된 워크플로우가 발생할 수 있습니다.
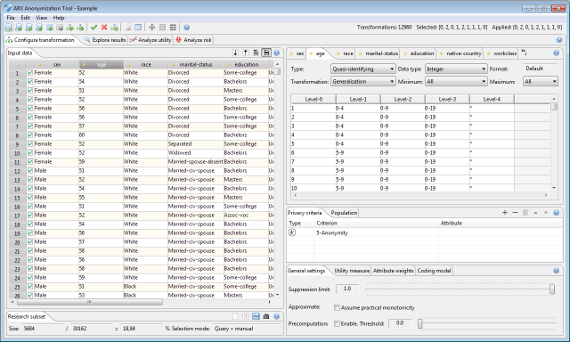
Configuration 관점
구성 관점에서 데이터를 가져오고, 변환 규칙을 만들 수 있으며, 품질 모델과 개인 정보를 선택하고 매개 변수화 할 수 있습니다. 입력 데이터는 항상 왼쪽에 표시됩니다.
데이터 가져 오기 마법사는 다양한 데이터 소스를 지원하며 데이터 유형 및 형식과 같은 메타 데이터를 지정할 수 있습니다. ARX는 CSV 파일, MS Excel 스프레드 시트 및 MS SQL, DB2, MySQL 또는 PostgreSQL과 같은 관계형 데이터베이스 시스템에서 데이터를 가져올 수 있습니다.
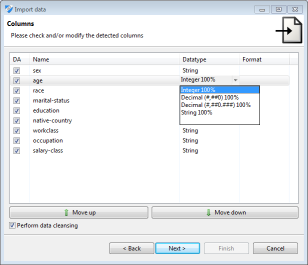
데이터 가져 오기 마법사는 열 이름 변경, 제거 및 순서 변경도 지원합니다. 데이터 가져 오기 중에 데이터 유형이 자동으로 감지되고 데이터 정리가 수행 될 수 있습니다. 즉, 지정된 데이터 유형을 따르지 않는 값은 ARX에서 구현 된 모든 메서드에서 올바르게 처리되는 특정 null 값으로 대체됩니다.
ARX가 표시하는 모든 테이블 형식 데이터는 컨텍스트 메뉴를 통해 CSV 파일로 내보낼 수 있습니다. ARX는 값 일반화 계층을 사용하여 다양한 데이터 변환 방법을 구현합니다. 이러한 계층은 소프트웨어 내에서 (특정 마법사를 통해) 생성하거나 CSV 파일에서 가져올 수 있습니다. ARX로 생성된 계층을 CSV 파일로 내보낼 수도 있습니다.
Exploration 관점
익명화 프로세스 중에 ARX는 입력 데이터 세트의 잠재적 변환에 대한 솔루션 공간을 특성화합니다. 각 솔루션 후보에 대해 위험 임계값이 충족되는지 여부가 결정되고 주어진 모델에 따라 데이터 품질이 정량화됩니다. 이 관점을 통해 사용자는이 프로세스의 결과를 탐색하고 추가 분석을 위해 흥미로운 변환을 선택할 수 있습니다.
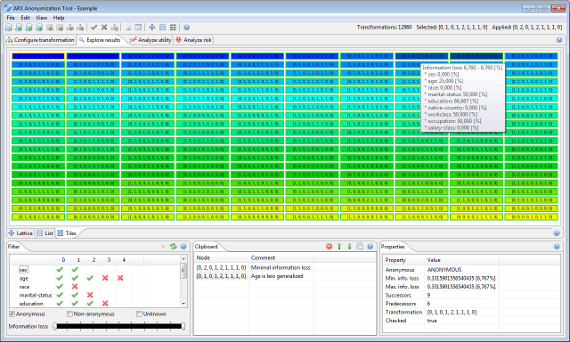
버전 3.7.0부터 ARX는 입력 데이터 세트의 다른 부분에 다른 변환 체계를 적용하는 로컬 변환 방법을 지원합니다. 이 경우 탐색 퍼스펙티브는 데이터 세트에 적용된 개별 변환을 표시합니다.
Utility analysis 관점
유틸리티 분석 관점을 사용하여 예상 사용 시나리오에 대한 특정 변환의 적합성을 평가할 수 있습니다. 이를 위해 입력 데이터와 변환 된 데이터가 나란히 표시됩니다. 또한 기술 통계를 계산하고 분류 모델을 생성하기위한 학습 세트로서 출력 데이터의 적합성을 분석 할 수 있습니다. 해석을 돕기 위해 다양한 그래픽 및 수치 표현이 표시됩니다.
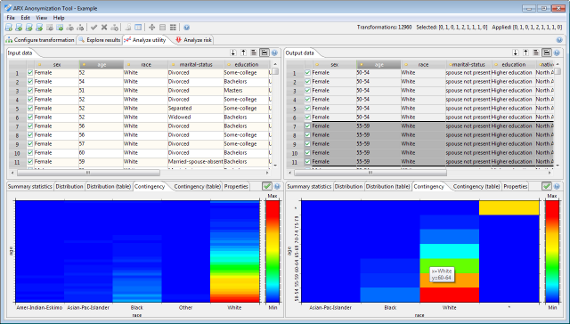
유틸리티 분석 퍼스펙티브는 출력 데이터 세트에 로컬 변환을 적용하는 데 사용할 수있는보기도 제공합니다. 이 기능은 일반적으로 ARX 3.7.0 이상에서 필요하지 않으며 향후 제거 될 수 있습니다.
Risk analysis 관점
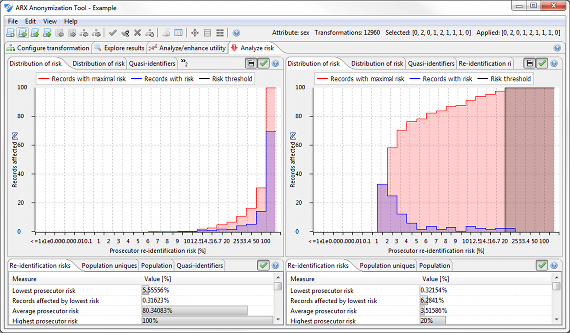
이러한 관점에서 프라이버시 위험을 반영하는 다양한 메트릭이 제시됩니다. ARX에 의해 구현된 지표에는 검사, 언론인 및 마케팅 담당자 공격에 대한 재식별 위험과 다양한 통계 모델을 사용하여 계산할수 있는 인구 고유성 추정이 포함됩니다. 또한 이 관점은 미국 건강 보험 이동성 및 책임법 (HIPAA 식별자)의 Safe Harbor 방법에 따라 수정해야하는 속성을 감지하는 방법과 추가 유사 식별자를 감지하는 방법에 대한 액세스를 제공합니다.
Configuration (구성)
Configuring the anonymization process (익명화 프로세스 구성)
구성 관점에서 데이터를 가져오고 변환 규칙, 개인 정보 보호 모델 및 유틸리티 측정을 선택하고 매개 변수화 할 수 있습니다.
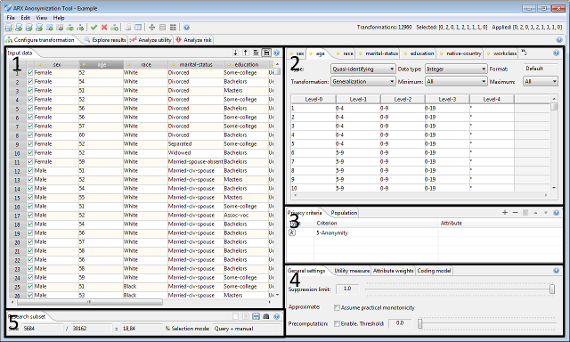
관점은 5 개의 주요 영역으로 나뉩니다.
영역 1 은 현재 입력 데이터 세트를 보여줍니다.
- 테이블에는 지정된 속성 메타 데이터에 대한 추가 정보가 표시됩니다.
영역 2 는 속성 메타 데이터를 지정하고 일반화 계층을 볼 수 있는 방법을 제공합니다.
- 속성 유형 및 데이터 유형을 지정할 수 있습니다.
- 일반화 계층을 수정할 수 있습니다.
영역 3 은 프라이버시 모델의 구성을 지원합니다.
- 여러 개인 정보 보호 모델을 선택하고 구성 할 수 있습니다. 추가 매개 변수는 전용 탭에서 지정할 수 있습니다.
영역 4 는 유틸리티 측정 구성을 지원합니다.
- 단일 유틸리티 측정을 목적 함수로 구성하고 선택할 수 있습니다.
영역 5 는 연구 샘플을 추출하는 방법을 제공합니다.
- 이 개념으로 ARX는로드 된 데이터 세트의 샘플로 익명화 될 데이터 세트를 정의하여 모집단 테이블의 사양을 지원합니다.
- 샘플은 수동으로 선택하거나, 무작위로 그리거나, 쿼리 또는 다른 데이터 세트와 일치시켜 선택할 수 있습니다.
Tables representing input and output data (입력 및 출력 데이터를 나타내는 테이블)
ARX는 다양한 색상으로 속성 유형을 나타내는 헤더가있는 특수 테이블에 입력 및 출력 데이터를 표시합니다.
- 빨간색은 식별 속성을 나타냅니다 .
- 노란색은 유사 식별 속성을 나타냅니다 .
- 자주색은 민감한 속성을 나타냅니다 .
- 녹색은 민감하지 않은 속성을 나타냅니다 .
각 레코드는 확인란과 추가로 연결됩니다. 이 확인란은 지정된 연구 샘플에 포함 된 레코드를 나타냅니다. 출력 데이터 세트에 대한 보기의 확인란은 익명화 프로세스가 마지막으로 실행되었을 때 지정된 샘플을 나타냅니다. 편집 할 수 없습니다. 입력 데이터 세트보기의 확인란은 현재 연구 샘플을 나타냅니다. 편집 가능합니다.

각 테이블은 오른쪽 상단의 버튼을 통해 액세스 할 수있는 몇 가지 옵션을 제공합니다.
- 첫 번째 버튼은 현재 선택한 열에 따라 데이터를 정렬합니다.
- 두 번째 버튼은 모든 유사 식별자에 따라 출력 데이터 세트를 정렬 한 다음 등가 클래스를 강조 표시합니다.
- 세 번째 버튼은 모든 레코드를 표시할지 또는 연구 샘플에 포함 된 레코드 만 표시할지 여부를 제어합니다.
Specifying attribute properties (Attribute 속성 지정)
Attribute 속성은 이 Perspective 내의 “데이터 변환” 및 “속성 메타 데이터”탭에서 설정할 수 있습니다. 속성의 속성을 설정하려면 먼저 데이터 세트의 표 형식보기에서 속성을 선택해야합니다. 탭의보기는 선택한 속성과 연결되고 그에 따라 업데이트됩니다.

Data transformation (데이터 변환)
변환 탭을 사용하여 속성 유형 및 관련 변환 방법을 설정할 수 있습니다. 변환 탭은 속성의 일반화 계층도 표시하고 내부 편집을위한 상황에 맞는 메뉴를 제공합니다.
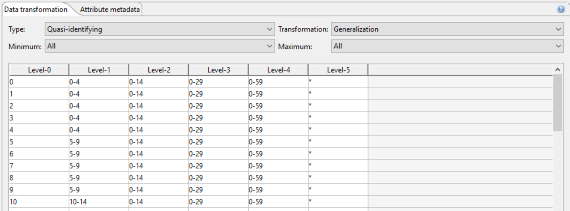
지원되는 속성 유형 :
- 식별 속성 은 데이터 세트에서 제거됩니다.
- 유사 식별 속성 이 변환됩니다.
- 민감한 속성 은 그대로 유지되지만 t- 근접성 또는 l- 다양성과 같은 프라이버시 모델을 사용하여 보호 할 수 있습니다.
- 민감하지 않은 속성 은 수정되지 않은 상태로 유지됩니다.
참고 : 지정된 속성 유형은 입력 탭의 속성 이름 옆에 색상 코드 글 머리 기호로도 표시됩니다.
참고 : 버전 3.7.0부터는 특정 속성 유형을 데이터 세트의 모든 속성에 할당하는 데 사용할 수있는 특정 버튼도 있습니다.

지원되는 변환 방법에는 일반화, 미세 집계 및 억제가 포함됩니다. 일반화를 선택하면 최소 및 최대 일반화 수준을 지정할 수 있습니다. 마이크로 집계는 지정된 값 일반화 계층을 사용하여 사전 클러스터링을 사용하거나 사용하지 않고 수행 할 수 있으며 집계 함수 및 누락 된 값 처리 방법을 지정할 수 있습니다.
관련 값 일반화 계층은 표 형식으로 표시됩니다. 원래 속성 값은 가장 왼쪽 열에 표시되며 일반화 수준은 왼쪽에서 오른쪽으로 증가합니다. 테이블을 마우스 오른쪽 버튼으로 클릭하면 편집 기능에 액세스 할 수있는 컨텍스트 메뉴가 나타납니다. 이것은 단순한 계층을 생성하거나 기존 계층을 간단하게 수정하는 데 사용할 수 있습니다. 또한 속성 억제를 나타내는 계층을 만들 수 있습니다. 더 복잡한 계층을 만들기 위해 ARX는 응용 프로그램 메뉴와 도구 모음에서 실행할 수있는 여러 마법사를 지원 합니다.
Attribute metadata (속성 메타 데이터)
이보기는 속성의 데이터 유형 (형식 포함)을 지정하는 데 사용할 수 있습니다. 계층 생성에 대부분의 마법사를 사용하려면 올바른 데이터 유형이 필요합니다.
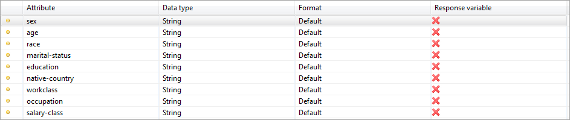
지원되는 데이터 유형 :
- String(문자열): 일반 문자 시퀀스입니다. 기본 데이터 유형입니다.
- Integer(정수): 부분 성분이 없는 숫자에 대한 데이터 유형입니다.
- Decimal(십진수): 부분 성분이 있는 숫자에 대한 데이터 유형입니다.
- Date/Time(날짜/시간): 날짜에 대한 데이터 유형입니다(시간이 있거나 없는 날짜).
- Ordinal(순서형): 순서형 척도가 있는 문자열 변수입니다.
테이블에서 속성의 행을 마우스 오른쪽 버튼으로 클릭하여 데이터 유형을 설정할 수 있습니다. 필요한 경우 ARX는 적절한 형식 문자열을 요청합니다. 데이터 유형을 지정하는 것은 선택 사항이지만 일반화 계층을 생성하고 분석 관점에서 데이터를 시각화 할 때 더 나은 결과를 제공합니다.
변수는 출력 데이터를 사용하여 수행할 모델링 작업에서 “반응 변수(response variables)”로 정의할 수 있습니다. 그런 다음 적절한 데이터 품질 모델과 결합하면 ARX는 준 식별 변수와 지정된 반응 변수 간의 구조적 관계에 미치는 영향을 최소화합니다.
Creating generalization hierarchies (일반화 계층 만들기)
ARX는 다양한 유형의 속성에 대한 일반화 계층을 생성하는 다양한 방법을 제공합니다. 마법사로 생성 된 일반화 계층은 함수로 저장됩니다. 즉, 구체적인 데이터 세트의 특정 값을 명시 적으로 지정하지 않고도 속성의 전체 도메인에 대해 생성 할 수 있습니다. 이를 통해 연속 변수를 처리 할 수 있습니다. 또한 계층 사양을 가져오고 내보낼 수 있으므로 유사한 속성을 가진 다른 데이터 세트를 익명화하는 데 재사용 할 수 있습니다. 마법사를 사용하기 전에 적절한 데이터 유형을 지정하는 것이 중요합니다. 마법사를 사용하여 네 가지 유형의 계층을 만들 수 있습니다.
- Masking-based hierarchies(마스킹 기반 계층 구조) :이 범용 메커니즘을 통해 광범위한 속성에 대한 계층 구조를 만들 수 있습니다.
- Interval-based hierarchies(간격 기반 계층 구조) : 이러한 계층 구조는 비율 척도가있는 변수에 사용할 수 있습니다.
- Order-based hierarchies(순서 기반 계층 구조) :이 방법은 순서 척도가있는 변수에 사용할 수 있습니다.
- Date-based hierarchies(날짜 기반 계층) :이 방법은 날짜에 사용할 수 있습니다
Masking-based hierarchies (마스킹 기반 계층)
마스킹은 다양한 유형의 속성에 적용 할 수있는 유연한 메커니즘이며 특히 우편 번호와 같은 영숫자 코드에 적합합니다. 다음 이미지는 각 마법사의 스크린 샷을 보여줍니다.
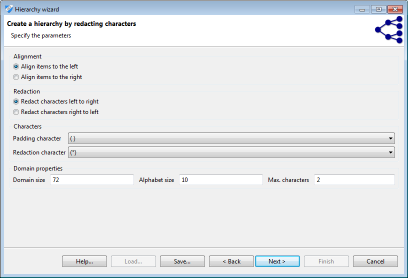
마법사에서 마스킹은 2 단계 프로세스를 따릅니다. 첫째, 값은 왼쪽 또는 오른쪽으로 정렬됩니다. 그런 다음 문자가 다시 왼쪽에서 오른쪽으로 또는 오른쪽에서 왼쪽으로 마스크됩니다. 패딩 문자를 추가하여 모든 값을 공통 길이로 조정합니다. 이 문자와 마스킹에 사용되는 문자는 사용자가 지정할 수 있습니다.
Interval-based hierarchies (간격 기반 계층)
간격은 정수 또는 소수와 같은 비율 척도가있는 값에 대한 일반화의 자연스러운 수단입니다. ARX는 위의 데이터 유형 중 하나를 갖는 전체 변수 범위에 대해 간격 세트를 효율적으로 정의하기위한 그래픽 편집기를 제공합니다. 먼저 뷰의 왼쪽에 일련의 간격을 정의 할 수 있습니다. 다음 단계에서 이전 레벨의 간격 그룹으로 구성된 후속 레벨을 지정할 수 있습니다. 각 그룹은 이전 수준에서 주어진 수의 요소를 결합합니다. 속성의 전체 범위를 포함하기 위해 간격 또는 그룹의 순서가 자동으로 반복됩니다. 예를 들어 임의의 정수를 길이 10의 간격으로 일반화하려면 간격 [0, 10] 하나만 정의하면됩니다. 다음 수준에서 크기 2 그룹을 정의하고,
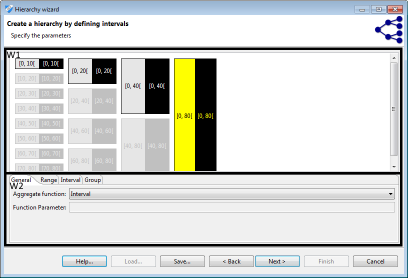
간격에 대한 레이블을 만들 수 있으려면 각 요소를 집계 함수 (W2)와 연결해야합니다. 다음 집계 함수가 지원됩니다.
- Set : 입력 값의 집합 표현이 반환됩니다.
- Prefix(접두사) : 입력 값의 접두사 집합이 반환됩니다. 매개 변수를 사용하면 이러한 접두사의 길이를 정의 할 수 있습니다.
- Common-prefix(공통 접두사) : 가장 큰 공통 접두사를 반환합니다.
- Bounds(경계) : 집합의 첫 번째 요소와 마지막 요소를 반환합니다.
- Interval(간격) : 최소값과 최대 값 사이의 간격이 반환됩니다.
- Constant(상수) : 미리 정의 된 상수 값을 반환합니다.
간격 또는 그룹을 클릭하면 매개 변수를 지정하는 데 사용할 수있는 편집기가 표시됩니다. 그래픽 표현을 마우스 오른쪽 버튼으로 클릭하여 요소를 제거, 추가 및 병합 할 수 있습니다. 간격은 최소 (포함) 및 최대 (제외) 경계로 정의됩니다. 그룹은 크기로 정의됩니다.
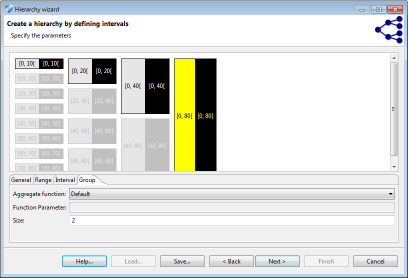
간격 기반 계층은 적용되는 범위를 정의 할 수 있습니다. “최소값”또는 “최대값”으로 정의 된 범위를 벗어난 값은 오류 메시지를 생성합니다. 이것은 온전성 검사를 구현하는 데 사용할 수 있습니다. 최소값 또는 최대값과 “하단 코딩(bottom coding)” 또는 “상단 코딩(top coding)”값 사이의 모든 값은 상단 또는 하단 코딩됩니다. 값이 하단 코딩 또는 상단 코딩 제한에서 “스냅” 제한까지 확장되는 간격에 속하면 하단 또는 상단 코딩 제한으로 확장됩니다. 나머지 범위 내에서 간격이 반복됩니다.
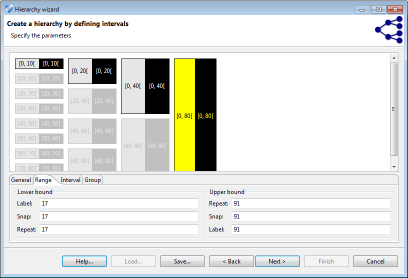
Order-based hierarchies (주문 기반 계층)
순서 기반 계층 구조는 간격 기반 계층 구조와 유사한 원칙을 따르지만, 순서 척도가 있는 속성에 적용 할 수 있습니다. 간격 기반 계층 구조에서 다루는 속성 유형 외에도 사전 순서 및 서수를 사용하는 문자열이 포함됩니다. 첫째, 도메인 내의 속성은 사용자 또는 데이터 유형에 의해 정의 된 대로 정렬됩니다. 둘째, 간격 기반 계층 구조에 사용되는 것과 유사한 메커니즘을 사용하여 정렬된 값을 그룹화 할 수 있습니다. 순서 기반 계층 구조는 특히 서수 문자열에 유용하므로 구체적인 데이터 세트에 포함된 값 대신 속성의 전체 도메인을 표시합니다. 이 메커니즘은 불연속 변수 도메인의 사전 정의된 의미 있는 순서에서 의미 계층을 생성하는 데 사용할 수 있습니다. 도메인 값의 후속 일반화는 사용자 정의 상수로 레이블을 지정할 수 있습니다.
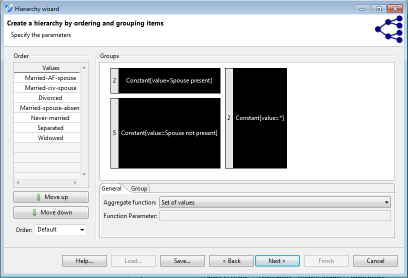
Date-based hierarchies (날짜 기반 계층)
이 마법사는 증가하는 일반화 수준에서 출력 데이터의 세분성을 지정하여 날짜에 대한 계층 구조 생성을 지원합니다. 계층 구조를 형성하는 세분화 수준을 지정하는 것이 중요합니다 (예 : 동일한 요일이 1년의 다른 주로 일반화 될 수 있기 때문에 일반적으로 요일 뒤에 연중 주가 올 수 없음). 이 제약 조건을 위반하면 ARX는 익명화 프로세스 중에 오류 메시지를 발생시킵니다.
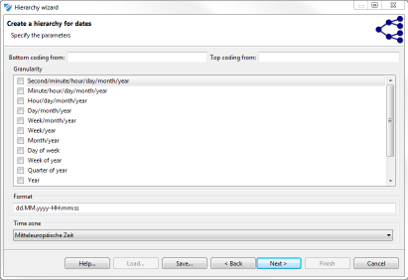
마지막 단계에서 모든 마법사는 현재 입력 데이터 세트의 결과 계층 구조를 표 형식으로 표시합니다. 또한 각 수준의 그룹 수가 계산됩니다. 프로세스에서 생성된 기능 표현은 유사한 속성을 가진 다른 데이터 세트에 대해 내보내고 재사용 할 수 있습니다.
개인 정보 보호 모델, 인구 속성, 데이터 공유의 비용 및 이점
다음보기에서 개인 정보 보호 모델을 선택하고 구성 할 수 있습니다.
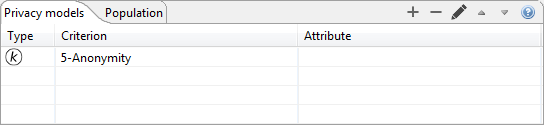
선택한 모델이 표에 표시됩니다. 더하기 또는 빼기 버튼을 각각 클릭하여 프라이버시 모델을 추가하거나 제거 할 수 있습니다. 세 번째 버튼은 매개 변수화를위한 대화 상자를 표시합니다.
대부분의 버튼은 다음 구성 대화 상자를 표시합니다. 여기에서 아래쪽을 가리키는 화살표를 사용하여 선택한 개인 정보 보호 모델에 대한 사전 설정 집합에서 매개 변수화를 선택할 수 있습니다.
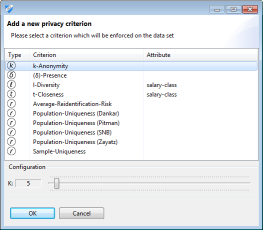
k-Anonymity, k-Map, Δ-presence, 위험 기반 개인 정보 모델, 차이점 개인 정보 보호 및 게임 이론적 모델은 준 식별자에 초점을 맞추므로 항상 사용할 수 있습니다. 반면, l-다양성, t-밀착성, β-리케네스 및 Δ-공개 프라이버시는 민감한 속성에 초점을 맞춥니다. 따라서 중요한 특성을 선택한 경우에만 활성화할 수 있습니다. 또한 일부 모델에서는 특정 설정이 필요합니다. 예를 들어, 계층적 접지 거리에 t-투명성을 사용할 수 있으려면 값 일반화 계층을 지정해야 합니다. 일부 개인 정보 보호 모델(예: k-map 및 Δ-presence)에는 익명화할 데이터 집합을 로드된 데이터 집합의 (연구) 샘플로 정의하여 ARX에서 지원하는 모집단 테이블이 필요합니다.
참고: 모집단 고유성에 기반한 모형을 사용하는 경우 기본 모집단의 특성도 지정해야 합니다. 이는 다음과 같은 관점에서 지원됩니다.

참고: 모집단 고유성에 기반한 모형은 데이터 집합이 모집단의 균일한 표본이라고 가정합니다. 그렇지 않을 경우 결과가 부정확할 수 있습니다.
참고: 게임 이데올로기 모델은 비용/편익 분석을 기반으로 하기 때문에 다음과 같은 관점에서 볼 수 있는 다양한 매개변수의 사양이 필요합니다.

여기에서 다음 매개 변수를 지정해야합니다.
- Adversary cost(상대 비용): 단일 레코드를 다시 식별하기 위해 공격자가 필요로 하는 금액입니다.
- Adversary gain(적대적 이득): 단일 레코드를 성공적으로 다시 식별하기 위해 공격자가 벌어들인 돈의 양입니다.
- Publisher benefit(게시자 혜택): 데이터 게시자가 단일 레코드를 게시하기 위해 번 돈입니다.
- Publisher loss(게시자 손실): 데이터 게시자가 손실한 금액입니다. 예를 들어, 하나의 레코드가 성공적으로 공격된 경우 벌금 때문에 손실된 금액입니다.
Transformation and utility model (변환 및 실용 신안)
이보기의 첫 번째 탭에서 변환 프로세스의 일반 속성을 지정할 수 있습니다.
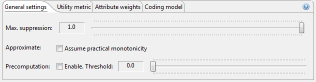
첫 번째 슬라이더를 사용하면 입력 데이터 집합에서 제거할 수 있는 최대 레코드 수인 억제 제한을 정의할 수 있습니다. 이 파라미터의 권장 값은 “100%”입니다. 근사치 옵션을 사용하면 실행 시간을 크게 단축할 수 있는 대략적인 솔루션을 계산할 수 있습니다. 솔루션은 지정된 개인 정보 설정을 이행하도록 보장되지만 지정된 데이터 유틸리티 모델에 대해서는 최적이 아닐 수 있습니다. 권장 설정은 “끄기”입니다. 일부 유틸리티 측정의 경우 사전 컴퓨팅 단계를 사용할 수 있으므로 실행 시간이 크게 단축될 수도 있습니다. 각 유사 식별자에 대해 고유한 데이터 값의 수를 데이터 집합의 총 레코드 수로 나눈 값이 구성된 임계값보다 낮은 경우 사전 컴퓨팅이 켜집니다. 실험 결과 0.3은 종종 이 모수에 대해 좋은 값인 것으로 나타났습니다. 권장 설정은 “끄기”입니다.
두 번째 탭에서는 익명화 프로세스 중에 최적화 기능으로 사용될 데이터 품질을 정량화하기위한 모델을 지정할 수 있습니다.
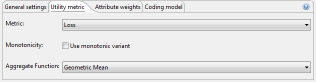
ARX는 지정된 모델을 사용하여 잠재적인 솔루션 후보자에게 “점수”를 할당합니다. 점수가 낮을수록 선택한 모델에 따라 데이터 품질, 정보 손실 감소, 게시자 지불 증가 또는 분류 정확도가 높아집니다. 그러나 이 점수는 ARX의 내부 최적화로 인해 모형이 반환하는 실제 값에서 크게 벗어날 수 있습니다. 따라서 데이터 품질을 설명하는 척도로 “점수”를 보고해서는 안 됩니다. 이러한 조치를 얻으려면 효용 분석 관점을 사용해야 합니다.
단소성은 익명화 프로세스를 보다 효율적으로 만들기 위해 이용할 수 있는 개인 정보 및 유틸리티 모델의 속성입니다. 그러나 실제 설정에서는 소프트웨어가 사용하는 변환 방법이 복잡하기 때문에 모델이 거의 단조롭지 않습니다. ARX는 항상 단조로움을 가정하도록 구성할 수 있으며, 이로 인해 익명화 프로세스가 상당히 빨라지지만 출력 데이터 품질이 크게 저하될 수도 있습니다. 권장 설정은 “끄기”입니다. ARX는 또한 많은 품질 모델에 대해 사용자 정의 집계 기능을 지원합니다. 이러한 집계 함수는 데이터 집합의 개별 특성에 대해 얻은 추정치를 전역 값으로 컴파일하는 데 사용됩니다. 권장 설정은 “산술 평균(Arithmetic mean)”입니다.
대부분의 모델은 다음보기를 사용하여 중요도를 지정하기 위해 속성에 지정할 수있는 가중치를 지원합니다.
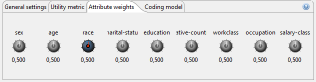
각 노브를 사용하여 특정 준 식별자에 가중치를 연결할 수 있습니다. 데이터 집합을 익명화할 때 ARX는 가중치가 높은 속성에 대한 정보 손실을 줄이려고 합니다.
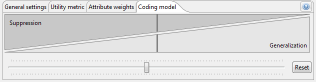
일부 품질 모델에서는 데이터를 변환할 때 일반화 또는 억제 여부를 지정할 수도 있습니다.
Defining a research sample (연구 샘플 정의)
이 보기에서는 연구 샘플을 지정할 수 있습니다. 익명화 및 내보낼 전체 데이터 집합의 샘플을 나타냅니다. 이 기능을 사용하여 모집단 테이블을 사용하여 데이터를 익명화할 수 있습니다. 이러한 정보를 고려할 수 있는 개인 정보 모델에는 Δ-presence, k-map 및 게임 이론적 접근 방식이 포함됩니다. 위험 분석을 위한 일부 방법에서도 고려됩니다. 오른쪽 상단 모서리의 버튼을 사용하면 데이터 집합에서 샘플을 추출하기 위한 다양한 옵션에 액세스할 수 있습니다.
- 기록을 선택하지 않습니다.
- 모든 레코드를 선택합니다.
- 현재 데이터 세트를 외부 데이터 세트와 일치시켜 레코드를 선택합니다.
- 데이터 세트를 쿼리하여 레코드를 선택합니다.
- 무작위 샘플링으로 레코드 선택.
보기에 현재 표본의 크기와 표본이 작성된 방법이 표시됩니다. 언제든지 데이터 테이블에 표시된 확인란을 클릭하여 연구 샘플을 변경할 수 있습니다. 쿼리 구문은 다음과 같습니다. 필드 및 상수는 작은 따옴표로 묶어야 합니다. 예제에서 ‘나이’는 필드이고 ‘50’은 상수입니다. 다음과 같은 연산자가 지원됩니다. >, >=, <, <=, =, 또는 ( and ) 이 대화 상자는 쿼리와 일치하는 행 수를 동적으로 표시하고 구문학적 오류가 발생할 경우 오류 메시지를 표시합니다.
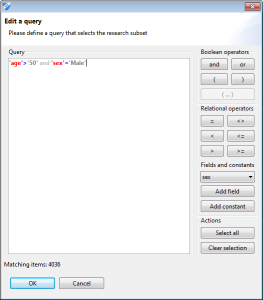
Project settings (프로젝트 설정)
설정 창은 애플리케이션 메뉴 또는 애플리케이션 도구 모음에서 액세스 할 수 있습니다.
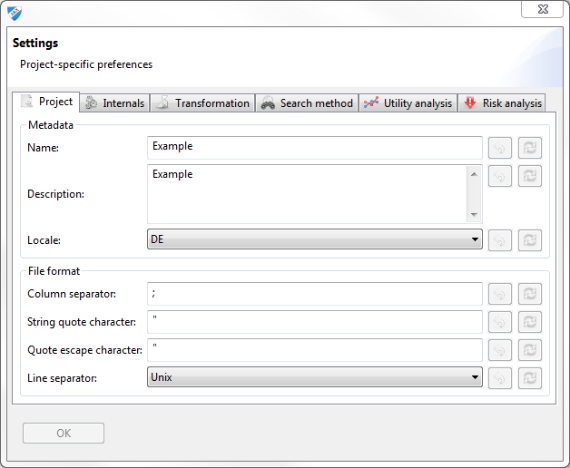
프로젝트 섹션은 일반적으로 프로젝트 속성을 변경하는 데 사용할 수 있습니다 :
- 이름, 설명 및 지역화를 포함한 메타 데이터를 투영합니다.
- CSV 가져오기 및 내보내기에 대한 구문입니다.
내부 구조의 부분은 성능 및 시각화 매개 변수를 조정하는 데 사용할 수 있습니다 :
- 스냅 샷 설정은 데이터 익명화 중 시공간 균형을 제어합니다. 더 큰 (상대적) 스냅 샷 크기는 일반적으로 실행 시간을 줄이지 만 메모리 소비를 증가시킵니다.
- 매우 큰 데이터 세트를 처리하는 경우 일부 분석 및 시각화를 비활성화 할 수 있습니다.
변환 섹션 변경 및 변환 된 데이터의 표현을 단순화하기위한 옵션을 제공한다 :
- 비익명 출력 데이터에 대해 레코드 억제를 활성화하거나 비활성화 할 수 있습니다.
- 민감하고 민감하지 않은 속성에 대해 속성 억제를 활성화하거나 비활성화 할 수 있습니다.
검색 방법 섹션은 검색 전략을 구성하고 기반 익명화 위험을 감수 할 수 있습니다 :
- 시간 제한을 사용한 휴리스틱 검색은 고차원 데이터에 대해 활성화 할 수 있습니다.
- 유틸리티 기반 레코드 억제를 비활성화하여 실행 시간을 개선 할 수 있습니다.
유틸리티 분석 부분은 발견 요약 통계 및 품질 측정에 사용할 수 있습니다 :
- 요약 통계는 목록 별 삭제 여부에 관계없이 계산할 수 있습니다.
- 익명화 프로세스 동안 기능 계층의 사용을 비활성화 할 수 있습니다.
- 분류 작업에 대한 출력 데이터의 유용성 분석 성능에 영향을 미치는 매개 변수가 변경 될 수 있습니다.
위험 분석 부 비선형 방정식 시스템 집적 솔버 구성 옵션을 제공한다 :
- 최적화 매개 변수에는 총 반복 횟수, 시도당 반복 횟수 및 필요한 정확도가 포함됩니다.
Performing the anonymization (익명화 수행)
ARX는 적절한 검색 전략을 선택하고, 변환 모델의 측면을 구성하고, 마지막으로 익명화 프로세스를 시작하기위한 전용 대화 상자를 제공합니다.
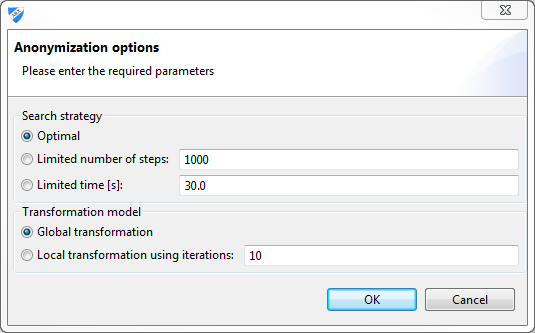
세 가지 검색 전략을 사용할 수 있습니다.
- 최적의 검색 전략입니다.
- 경험적 접근 검색 전략은 미리 정의된 검색 단계 수 이후에 종료됩니다.
- 경험적 발견 전략은 미리 정의된 시간 후에 종료됩니다.
최적의 검색 전략은 가장 높은 품질의 출력 데이터를 생성하는 변환을 안정적으로 결정하지만 대규모 데이터셋을 처리할 때 확장성 문제가 발생할 수 있습니다. 경험적 발견 전략은 종종 최적 전략을 매우 빠르게 결정할 수 있지만 최적성은 보장할 수 없습니다. 대규모 데이터셋의 경우 최상의 방식으로 작동합니다.
두 가지 다른 변환 모델이 지원됩니다.
- Global transformation(글로벌 변환) : 동일한 변환 전략이 데이터 세트의 모든 레코드에 적용됩니다.
- Local transformation(로컬 변환) : 데이터 세트에 있는 레코드의 다른 하위 집합에 다른 변환 전략을 적용 할 수 있습니다. 사용할 수있는 다른 변환 수에 대한 제한을 지정할 수 있습니다.
다양한 변환 모델을 개별 속성에 대한 다른 변환 규칙과 결합하여 다양한 변환 방법을 조합하여 사용할 수 있습니다.
- 글로벌 변환을 사용하여 (1) 전체 도메인 일반화, (2) 상위 및 하위 코딩(계층 편집기에 규칙에 따라 생성하기 위한 바로 가기가 있음), (3) 속성 억제(계층 편집기에 규칙에 따라 생성하기 위한 바로 가기가 있음), (4) 레코드 억제 및 (5) 마이크로 분리를 구현할 수 있습니다.
- 로컬 변환을 사용하여 (1) 전체 도메인 일반화(고정 일반화 수준을 정의함), (2) 상위 및 하위 코드화(고정 일반화 수준을 정의함), (3) 로컬 일반화, (4) 속성 억제(고정 일반화 수준을 정의함), (5) 셀 억제 및 (6) 마이크로 분리를 구현할 수 있습니다.
- 또한 구성 관점에서 각 보기에서 무작위 샘플링을 수행할 수 있습니다.
글로벌 변환이 로컬 변환보다 계산 비용이 적다는 것은 일반적으로 사실이 아니지만, 전자가 일반적으로 더 빠릅니다. 로컬 변환 방법의 각 반복에서 선택한 검색 전략이 사용됩니다. 그러나 각 반복에서 최적의 전략을 사용한다고 해서 반드시 로컬 변환을 통해 계산된 전체 솔루션이 최적이라는 것을 의미하지는 않습니다.
Exploration
Exploring the solution space (솔루션 공간 탐색)
이 관점에서 솔루션 공간을 찾아보고 입력 데이터 세트에 변환을 적용 할 수 있습니다.
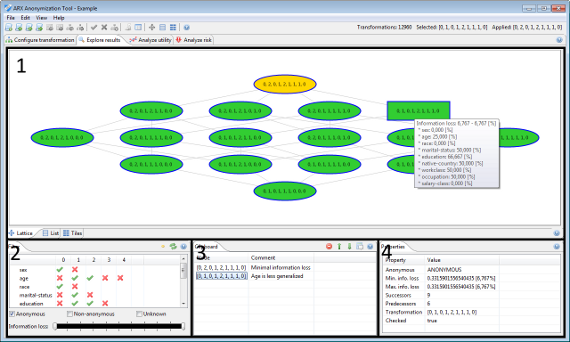
영역 1에는 현재 솔루션 공간의 하위 집합이 표시됩니다. 여기에 표시된 변환은 영역 2에 제공된 필터를 사용하여 선택할 수 있습니다. 영역 3은 변환을 저장하고 주석을 달 수 있는 클립보드를 구현하며 영역 4는 현재 선택한 변환의 속성을 표시합니다.
ARX의 응용 프로그램 도구 모음에는 메뉴 항목에 대한 일부 바로 가기 외에도 (1) 현재 선택된 변환, (2) 현재 적용된 변환 및 익명화 프로세스 중에 수집된 일부 통계와 같은 일부 정보가 표시됩니다. 이러한 통계에는 개인 정보 보호 변환 수와 솔루션 공간의 총 변환 수가 포함되며 검색 프로세스에 대한 일부 통계도 포함됩니다.
각 변환은 입력 데이터 집합의 유사 식별자에 대해 지정하는 일반화 수준에 의해 식별됩니다.
버전 3.7.0 ARX는 입력 데이터 세트의 여러 부분에 서로 다른 변환 방식을 적용하는 로컬 변환 방법을 지원하므로 참고하시기 바랍니다. 이 경우 탐색 관점에서는 데이터 집합에 적용된 개별 변환을 표시합니다.
Visualization of the solution space (솔루션 공간의 시각화)
화면 중앙에있는 보기에는 현재 솔루션 공간의 하위 집합이 표시됩니다. 솔루션 공간은 다양한 방식으로 시각화됩니다. 첫째, 기본 일반화 격자의 Hasse 다이어그램으로 표시 할 수 있습니다.
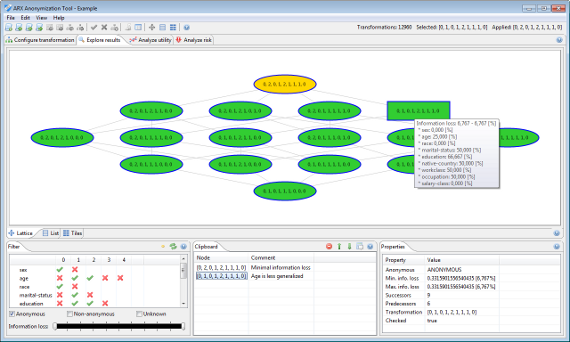
여기에서 각 노드는 입력 데이터 세트의 유사 식별자에 대해 지정하는 일반화 수준으로 식별되는 단일 변환을 나타냅니다. 변형은 세 가지 배경색으로 특징 지어집니다.
- 녹색은 개인 정보 보호 데이터 세트를 생성하는 변환을 나타냅니다.
- 빨간색은 개인 정보 보호 데이터 세트를 생성하지 않는 변환을 나타냅니다.
- 주황색은 지정된 유틸리티 측정과 관련하여 최적의 변환을 나타냅니다.
익명화 프로세스 중에 제거되지 않은 변환은 두꺼운 파란색 테두리로 표시됩니다. 왼쪽 버튼을 누른 상태에서 마우스를 끌면 시각화를 탐색할 수 있습니다. 오른쪽 버튼을 누른 상태에서 마우스를 끌면 현재 보기를 확대하거나 축소할 수 있습니다. 변환 위에 마우스를 놓으면 변환에 대한 기본 정보가 포함된 도구 설명이 표시됩니다. 왼쪽 버튼으로 변환을 클릭하면 변환이 선택되고 오른쪽 버튼으로 변환을 클릭하면 상황에 맞는 메뉴가 표시됩니다. 여기서 변환을 현재 입력 데이터 집합에 적용하거나 클립보드에 추가할 수 있습니다.
솔루션 공간은 목록으로 시각화 할 수도 있습니다.
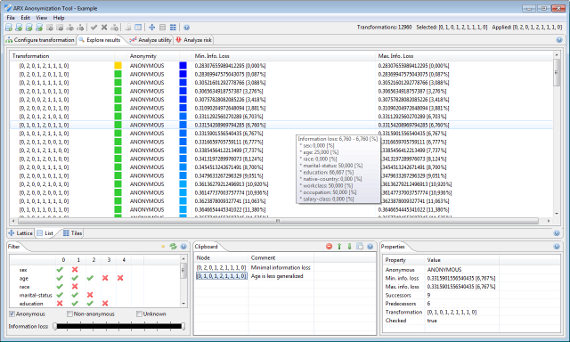
여기서 각 변환은 하나의 행으로 표시됩니다. 변환은 점수별로 정렬됩니다. 유틸리티 추정치 및 익명성 속성은 시각적으로 강조 표시됩니다.
마지막으로 솔루션 공간은 타일 세트로 시각화 할 수도 있습니다.
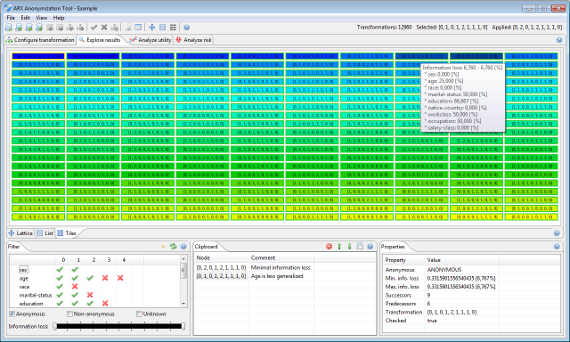
이 보기는 이전 단락에서 설명한 목록과 매우 유사합니다. 요소의 색상과 테두리는 익명 속성에 대한 정보를 인코딩하고 배경색은 데이터 유틸리티를 나타냅니다. 변환도 점수에 따라 정렬됩니다.
Filtering the solution space (솔루션 공간 필터링)
이 보기에서는 탐색 관점에서 표시될 솔루션 공간에서 일련의 변환을 선택할 수 있습니다. 변환은 특정 속성에 대한 특정 일반화 수준을 가진 사용자 또는 익명성 요구 사항을 충족하지 않거나 충족하지 않는 사용자로 제한될 수 있습니다.
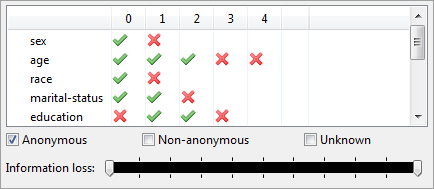
하단의 슬라이더를 사용하여 구성된 경계 사이에 있는 점수로 변환을 선택할 수 있습니다. 명시적으로 확인되지 않은 변환 점수는 알 수 없으며 따라서 솔루션 공간의 다른 변환에서 계산된 경계 구간으로 추정됩니다. 시간 제한이 있는 경험적 익명화 프로세스가 수행된 경우 이러한 추정치가 잘못될 수 있습니다.
버전 3.7.0 ARX는 입력 데이터 세트의 여러 부분에 서로 다른 변환 방식을 적용하는 로컬 변환 방법을 지원하므로 참고하시기 바랍니다. 이 옵션을 사용하면 이 보기가 비활성화됩니다.
Organizing transformations (변형 구성)
이 보기에는 변환을 구성하고 주석을 추가하는 데 사용할 수 있는 클립 보드가 포함되어 있습니다. 항목을 마우스 오른쪽 버튼으로 클릭하면 변환을 제거하고 현재 데이터 세트에 적용하고 주석을 편집 할 수 있는 컨텍스트 메뉴가 열립니다.
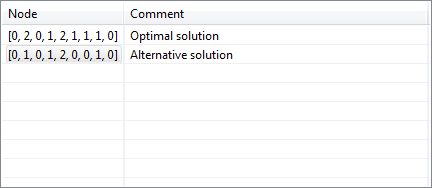
오른쪽 상단 모서리에 있는 버튼은 모든 항목 제거, 순서 변경 및 데이터 유틸리티 감소에 따른 정렬을 지원합니다.
버전 3.7.0부터 ARX는 입력 데이터 세트의 다른 부분에 다른 변환 체계를 적용하는 로컬 변환 방법을 지원합니다. 이 옵션을 사용하면 보기가 비활성화됩니다.
Properties of transformations (변형의 속성)
현재 선택한 변환에 대한 기본 정보가 보기에 표시됩니다. 최고 및 최저 점수는 절대값으로, 솔루션 공간에서 모든 변환의 최고 및 최저 점수에 상대적인 값으로 표시됩니다.
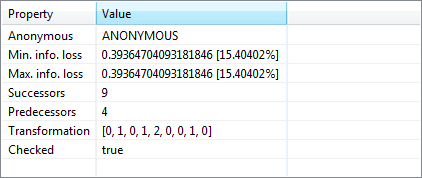
이 보기에는 변환의 후속 작업 및 선행 작업 수, 유사 식별자에 대해 지정된 일반화 수준 및 익명화 프로세스 중에 변환이 제거되었는지 여부도 표시됩니다.
버전 3.7.0부터 ARX는 입력 데이터 세트의 다른 부분에 다른 변환 체계를 적용하는 로컬 변환 방법을 지원합니다. 이 옵션을 사용하는 경우 보기는 영향을받는 레코드 수와 같은 적용된 개별 변환의 추가 속성을 표시합니다.
Utility analysis (유틸리티 분석)
Analyzing data utility (데이터 유틸리티 분석)
이러한 관점을 사용하여 예상 사용 시나리오에 대한 출력 데이터의 품질 및 효용을 분석할 수 있습니다. 이를 위해 변환된 데이터 집합을 원래 입력 데이터 집합과 비교할 수 있습니다. 상단에서 이 관점은 원본 데이터(면적 1)와 현재 선택한 변환의 결과(면적 2)를 표시합니다. 두 테이블 모두 수평 또는 수직 스크롤 막대를 사용하여 탐색할 때 동기화됩니다. 영역 3과 4에서는 현재 선택된 속성에 대한 통계 정보를 비교할 수 있습니다.
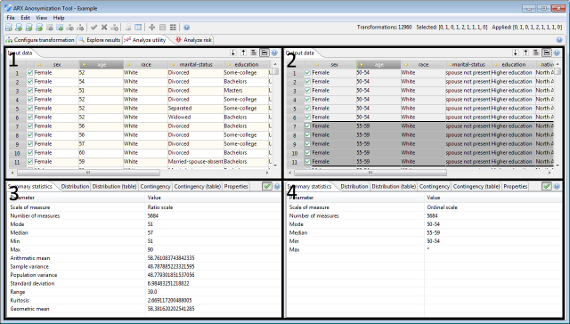
뷰에는 일변량 및 이변량 통계와 입력 및 출력 데이터 집합에 대한 기본 속성이 추가로 표시됩니다. 또한 동등성 클래스와 억제된 레코드의 분포에 대한 통계에 대한 액세스 권한을 제공합니다. 마지막으로, 건물 분류 모델에 대한 교육 세트로서 출력 데이터의 적합성을 분석할 수 있습니다.
참고: ARX는 원래 데이터셋과 변환된 데이터셋에 비교할 수 있는 데이터 시각화를 제공하려고 합니다. 이를 위해 속성의 데이터 유형 정보 및 일반화 계층에서 추출된 값 간의 관계를 사용합니다. 따라서 합리적인 데이터 유형과 계층 구조를 지정하면 데이터 시각화의 품질과 유용성이 향상됩니다.
Comparing input and output data (입력 및 출력 데이터 비교)
이 섹션에서는 변환된 데이터 집합을 원래 입력 데이터 집합과 비교할 수 있습니다. 두 테이블의 가로 및 세로 스크롤 막대가 동기화됩니다.
이 확인란은 어떤 행이 연구 샘플의 일부인지 나타냅니다. 출력 데이터 집합을 표시하는 표의 확인란은 익명화 프로세스가 수행될 때 선택한 샘플을 나타냅니다. 변경할 수 없습니다. 입력 데이터 집합을 표시하는 표의 확인란은 현재 연구 샘플을 나타냅니다. 편집 가능합니다.
각 테이블에는 보기 오른쪽 상단 모서리의 버튼을 통해 액세스할 수 있는 몇 가지 옵션이 있습니다.
- 첫 번째 버튼을 누르면 현재 선택한 속성에 따라 데이터가 정렬됩니다.
- 두 번째 버튼을 누르면 모든 유사 식별자에 따라 출력 데이터 집합이 정렬된 다음 동등성 클래스가 강조 표시됩니다.
- 세 번째 버튼을 누르면 데이터 집합의 모든 레코드가 표시되는지 또는 연구 샘플의 일부인 레코드만 표시되는지 전환됩니다.

Summary statistics (요약 통계)
유틸리티 분석 관점 하단의 첫 번째 탭에는 현재 선택한 속성에 대한 요약 통계가 표시됩니다.
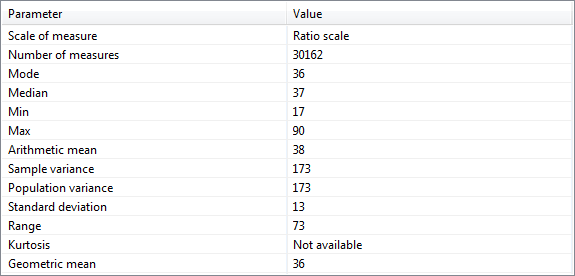
표시되는 파라미터는 변수의 측정 척도에 따라 달라집니다. 공칭 척도를 갖는 속성의 경우 다음 파라미터가 제공됩니다.
- 모드(Mode).
순서형 척도가 있는 속성의 경우 다음과 같은 추가 파라미터가 표시됩니다.
- 중위수(Median), 최소값(minimum), 최대값(maximum).
구간 척도가 있는 속성의 경우 다음과 같은 추가 매개변수가 제공됩니다.
- 산술 평균(Arithmetic mean), 표본 분산(sample variance), 모집단 분산(population variance), 표준 편차(standard deviation), 범위(range), 첨도(kurtosis).
비율 척도가 있는 속성의 경우 다음과 같은 추가 파라미터가 표시됩니다.
- 기하 평균(Geometric mean).
참고: 이러한 통계 매개변수는 결측 데이터를 처리하는 방법인 목록 삭제 방법을 사용하여 계산됩니다. 이 방법을 사용하면 단일 값이 누락된 경우 전체 레코드가 분석에서 제외됩니다. 이 동작은 프로젝트 설정에서 변경할 수 있습니다.
Empirical distribution (경험적 분포)
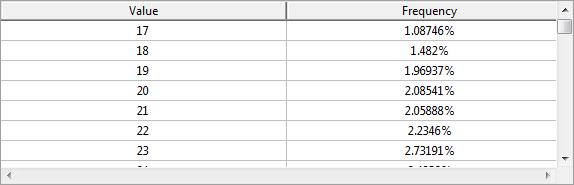
이 보기에는 현재 선택한 속성의 값의 빈도 분포를 시각화하는 히스토그램 또는 표가 표시됩니다.
위키피디아에서 다음을 제공합니다. 통계에서 빈도 분포는 표본에서 다양한 결과의 빈도를 표시하는 표입니다. 표의 각 항목에는 특정 그룹 또는 구간 내 값의 발생 빈도 또는 개수가 포함되며, 이러한 방식으로 표에는 표본의 값 분포가 요약됩니다.
위키피디아에서 다음을 제공합니다. 히스토그램은 숫자 데이터의 분포를 그래픽으로 표현한 것입니다. 연속형 변수의 확률 분포에 대한 추정치입니다. 히스토그램을 구성하기 위해 첫 번째 단계는 값의 범위(즉, 값의 전체 범위를 일련의 구간으로 나눈 다음 각 구간에 포함되는 값의 수를 세는 것입니다.
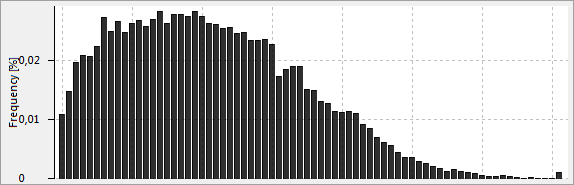
참고: ARX는 원본 및 변환된 데이터 세트의 속성에 대해 비교할 수 있는 데이터 시각화를 제시하려고 합니다. 이를 위해 일반화 계층 구조에서 추출한 속성의 데이터 유형 및 값 사이의 관계를 정보로 사용합니다. 따라서 합리적인 데이터 유형과 계층 구조를 지정하면 데이터 시각화의 품질과 비교 가능성을 높일 수 있습니다.
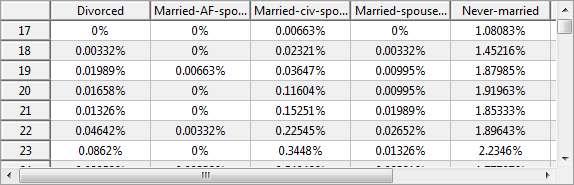
Contingency (우연성)
이 보기에는 선택한 두 속성의 분할 영역을 시각화하는 열 지도 또는 표가 표시됩니다.
분할은 변수의 다변량 빈도 분포를 나타냅니다.
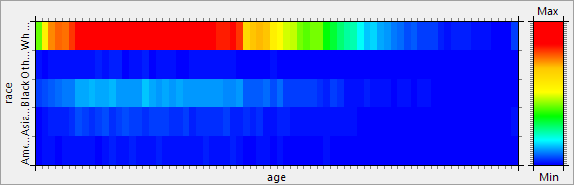
참고: ARX는 원본 및 변환된 데이터 세트의 속성에 대해 비교할 수 있는 데이터 시각화를 제시하려고 합니다. 이를 위해 일반화 계층 구조에서 추출한 속성의 데이터 유형 및 값 사이의 관계를 정보로 사용합니다. 따라서 합리적인 데이터 유형과 계층 구조를 지정하면 데이터 시각화의 품질과 유용성이 향상됩니다.
Equivalence classes and records (등가 클래스 및 레코드)
이 보기는 데이터 집합의 레코드에 대한 정보를 요약합니다. 동등성 클래스의 최소 크기, 최대 크기 및 평균 크기, 클래스 수, 억제 및 남은 레코드 수를 표시합니다.
“등가 클래스(equivalence class)”는 지정된 유사 식별 변수와 관련하여 구별할 수 없는 일련의 레코드를 설명합니다. 때때로 동등성 클래스를 “셀(cells)”이라고도 합니다.
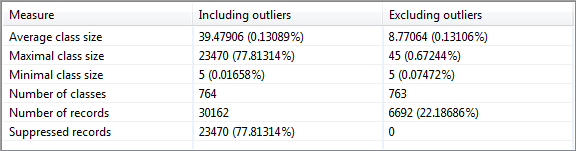
출력 데이터 집합의 경우 모든 파라미터는 두 가지 변형으로 계산됩니다. 한 변종은 억제된 레코드를 고려하며 다른 변종은 억제된 레코드를 무시합니다.
참고: 억제된 레코드를 무시하는 변종에서는 결측 데이터를 처리하는 방법인 목록 삭제 기능을 사용합니다. 이 방법에서는 단일 값이 결측된 경우 전체 레코드가 분석에서 제외됩니다.
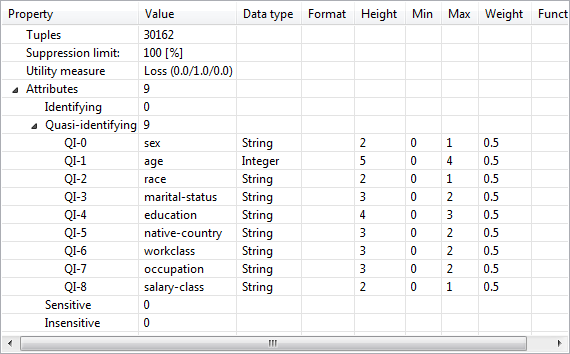
Properties of input data (입력 데이터의 속성)
이 보기에는 입력 데이터 집합과 익명화에 사용되는 구성에 대한 기본 속성이 표시됩니다. 이러한 속성에는 관련 변환 방법에 대한 데이터를 포함하여 데이터 집합에 있는 모든 속성의 얕은 사양뿐만 아니라 레코드 수 및 억제 한계도 포함됩니다.
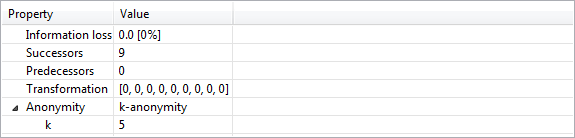
Properties of output data (출력 데이터의 속성)
이 보기에는 선택한 데이터 변환에 대한 기본 속성과 결과 출력 데이터 집합이 표시됩니다. 이러한 속성에는 지정된 효용 측정값 및 추가 설정(예: 속성 가중치), 억제된 레코드 수, 동등성 클래스 수 및 억제된 레코드를 포함하는 클래스 수가 포함됩니다. 개인 정보 보호를 위한 변환인 경우 모든 개인 정보 보호 모델의 전체 사양이 제공됩니다.
참고: 이 보기에서 제공되는 정보는 익명화 프로세스를 수행하기 전에 구성 관점에서 정의된 사양을 기반으로 합니다. 이러한 정의가 변경되더라도 워크벤치의 상태는 변경되지 않습니다. 변경사항을 적용하려면 데이터 익명화 프로세스를 다시 실행해야 합니다.
Classification performance (분류 성능)
이 뷰는 분류 모델과 해당 파라미터를 구성할 뿐만 아니라 입력 및 익명화된 출력 데이터에 대해 교육받은 모델의 성능을 비교하는 데 사용할 수 있습니다. ARX는 모델 생성을 위한 교육 세트로서 적합성을 향한 출력 데이터를 최적화하기 위해 특정 품질 모델을 지원합니다.
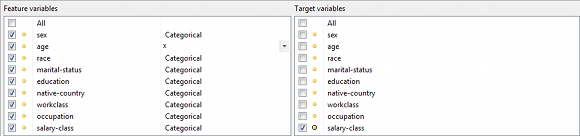
왼쪽 하단에 표시되는 뷰에서 피쳐 및 대상 변수를 선택하고 피쳐 스케일링 기능을 지정할 수 있습니다.
오른쪽 하단에 표시된 보기에서 서로 다른 유형의 분류 모델을 선택하고 구성할 수 있습니다.
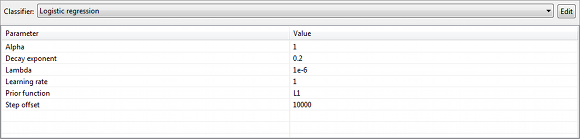
ARX는 현재 다음과 같은 유형의 분류 모델을 지원합니다.
- 로지스틱 회귀 분석(Logistic regression)
- Random fores)
- Naive Bayes
맨 위에서 탭(“개요” 및 “ROC 곡선”)으로 서로 다른 두 보기를 선택할 수 있습니다. 입력 및 출력 데이터의 경우 이러한 보기는 성능 분석의 다른 결과를 보여 줍니다. 성능 측정은 일반적으로 수정되지 않은 입력 데이터에 대해 교육된 사소한 ZeroR 분류기의 성능과 관련하여 표현되며, 선택한 유형의 모델도 입력 데이터에 대해 교육됩니다. 결과는 k-폴드 교차 검증을 사용하여 얻습니다.
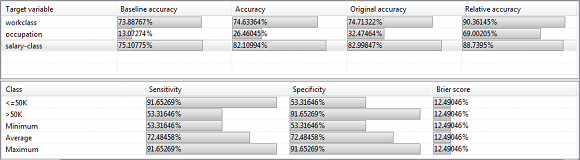
“개요” 보기의 표에는 (상대적) 분류 정확도와 함께 민감도, 특수성 및 Brier 점수가 표시됩니다.
“ROC 곡선” 보기의 그림 및 표에는 ROC 곡선과 대상 변수의 선택된 인스턴스에 대한 ROC 곡선(AUC) 아래의 영역이 표시됩니다.
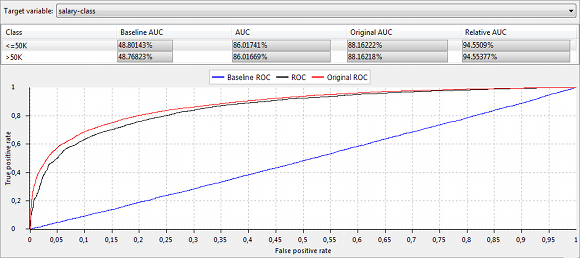
ARX는 일대 다 접근 방식을 사용하여 다항 분류기의 성능 측정 값을 계산합니다.
Data quality models (데이터 품질 모델)
이 절에서는 다양한 범용 모델을 사용하여 출력 데이터에 대해 얻은 데이터 품질 측정값을 표시합니다. 또한 속성의 데이터 유형과 결측값의 비율이 표시됩니다.
위쪽의 보기는 개별 준 식별자와 관련된 특성 수준 품질, 즉 품질 추정치를 보여줍니다. 아래쪽의 보기는 데이터 수준 품질, 즉 전체 유사 식별자 집합에 대한 품질 추정치를 보여줍니다.
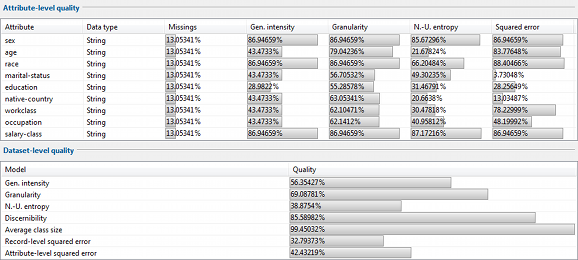
모든 품질 측정이 모든 속성 또는 데이터셋에 대해 반드시 지원되는 것은 아닙니다. 속성에 대해 품질 측정을 평가할 수 없는 경우, 결과는 상단 표에 “N/A”로 표시됩니다. 따라서 이 속성은 동일한 모형을 사용하여 데이터 수준 품질을 계산할 때도 무시되었습니다.
현재 다음과 같은 특성 수준 품질 모델이 구현되어 있습니다.
- 정밀도(Precision) : 속성 값의 일반화 강도를 측정합니다. 자세한 내용은 다음을 참조합니다. 스위니, L.입니다. 일반화 및 억제를 사용하여 k-익명성 개인 정보 보호를 실현합니다.
- 세분화(Granularity): 데이터의 세분화를 캡처합니다. 자세한 내용은 다음을 참조합니다. 아이옌가르, 브이시입니다. 개인 정보 보호를 위해 데이터를 변환합니다.
- 균일하지 않은 엔트로(Non-Uniform Entropy) : 속성 값 분포의 차이를 수량화합니다. 식별되지 않은 상태 데이터의 품질을 평가하기 위한 일반 방법입니다.
- 오차 제곱(Squared error) : 값을 숫자로 해석하고 구분할 수 없는 레코드 그룹에서 오차 제곱의 합을 캡처합니다.
또한 다음과 같은 데이터 집합 수준 품질 모델을 사용할 수 있습니다.
- 평균 클래스 크기(Average class size) : 구분할 수 없는 레코드 그룹의 평균 크기를 측정합니다.
- 식별 가능(Discernibility) : 구별할 수 없는 레코드 그룹의 크기를 측정하고 완전히 억제된 레코드에 대해 벌칙을 도입합니다.
- 모호성(Ambiguity) : 레코드의 모호성을 캡처합니다.
- 레코드 수준 제곱 오류(Record-level squared error) : 레코드를 벡터로 해석하고 구분할 수 없는 레코드 그룹에서 오차 제곱의 합을 캡처합니다.
Local recoding (로컬 레코딩)
ARX의 유틸리티 분석 관점의 이 섹션에서는 사용자가 로컬 변환(예: 일반화 및 집계)을 수행하여 기본 익명화 절차를 통해 얻은 출력 데이터의 품질을 더욱 향상시킬 수 있습니다. 100%의 억제 한계와 다른 유형의 데이터 변환보다 억제를 선호하는 구성을 사용하여 기본 익명화를 수행하는 것이 좋습니다. 후자는 구성 원근의 “코딩 모델” 섹션에 있는 슬라이더를 맨 왼쪽 위치로 이동하여 구성할 수 있습니다. 그런 다음 다양한 방법으로 로컬 재코딩을 수행할 수 있습니다. 기본 구성을 사용하는 것이 좋습니다(슬라이더가 거의 왼쪽으로 이동됨, 방법: 매개 변수 0.05의 fixpoint 적응형).
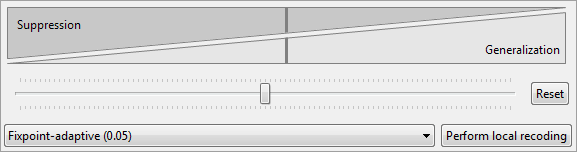
ARX는 이전 반복에서 억제된 레코드에 대해 글로벌 변환 알고리즘을 재귀적으로 실행하여 로컬 재코딩을 수행합니다. 이 방법을 사용하면 다른 로컬 변환 알고리즘과 비교하여도 데이터 품질을 크게 개선할 수 있습니다. 또한 이 방법은 속성 노출로부터 데이터를 보호하기 위한 모델을 포함하여 다양한 개인 정보 보호 모델을 지원합니다.
ARX 버전 3.7.0부터는 로컬 변환이 더 명시적으로 지원되며 일반적으로 이 보기는 더 이상 필요하지 않습니다.
Risk analysis (위험도 분석)
Analyzing risks (위험 분석)
이러한 관점에서 다양한 프라이버시 리스크를 분석할 수 있습니다. 여기에는 검사, 언론인 및 마케터 공격자 모델의 재식별 위험뿐만 아니라 다양한 통계적 방법으로 추정할 수 있는 인구 특성에서 파생된 위험도 포함됩니다. 또한 데이터 집합에서 HIPAA 식별자를 탐지하고 추가 유사 식별자를 찾는 방법을 제공합니다.

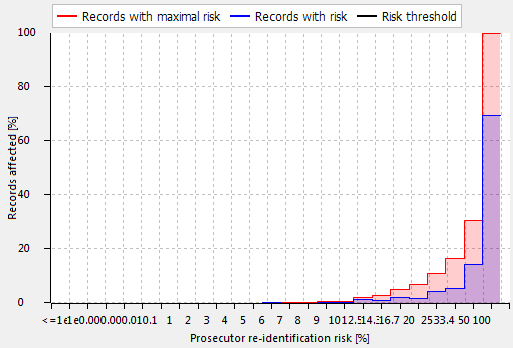
Distribution of risks (위험 분배)
이 보기에서는 데이터 집합의 레코드 간에 재식별 위험의 분포가 표시됩니다. 분포는 입력 및 출력 데이터 모두에 대해 히스토그램 또는 표로 계산됩니다.
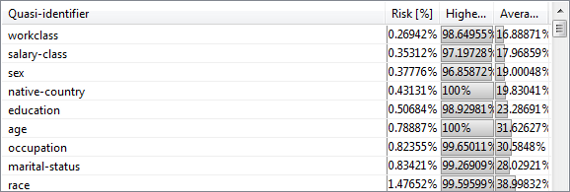
Finding quasi-identifiers (유사 식별자 찾기)
이 보기에서는 재식별의 관련 위험과 관련하여 속성 조합을 분석할 수 있습니다. 보기는 변수 조합이 레코드를 서로 구분하는 정도와 변수를 통해 레코드를 구별하는 정도에 대한 정보를 제공합니다. 먼저 왼쪽 아래 영역에서 추가 분석을 위해 특성 집합을 선택해야 합니다.

그런 다음 ARX는 앞서 언급한 파라미터를 계산합니다.
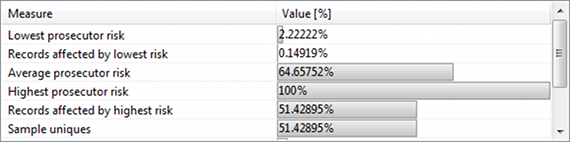
Re-identification risks (재식별 위험)
이 보기에서는 위험 재식별을 위한 몇 가지 조치에 대한 개요를 표시합니다. 이러한 관점의 상위 영역에서는 (1) 검사 시나리오, (2) 언론인 시나리오 및 (3) 마케터 시나리오의 세 가지 공격자 모델에 대한 리스크 추정치가 제공됩니다.
임계값은 모든 레코드의 가장 높은 위험, 이 임계값보다 높은 위험을 가진 레코드 및 성공적으로 재식별할 수 있는 평균 레코드 부분에 대해 제공할 수 있습니다. 이 방법에 대한 자세한 내용은 칼레드 엘 에맘의 개인 건강 정보 익명화에 대한 안내서에서 확인할 수 있습니다.
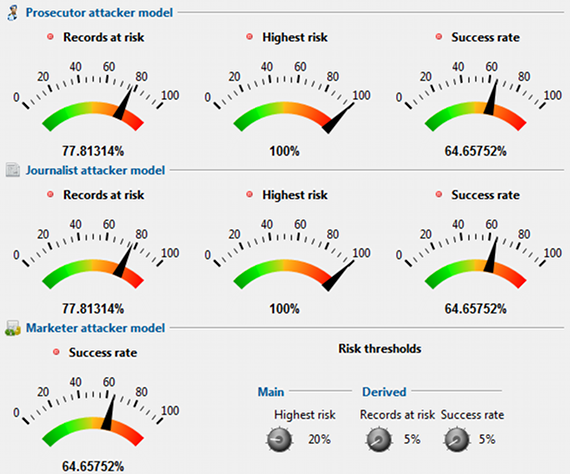
하단에는 검사 재식별 리스크에 대한 선별된 대책이 표시됩니다. 이러한 측정값은 표본 자체를 기반으로 합니다. 이 값은 선택한 통계 모형의 모집단 고유성에 대한 숫자로 보완됩니다.
- 가장 낮은 검사들은 재식별 리스크.
- 가장 낮은 위험의 영향을 받는 개인.
- 최고 검사들이 재식별 위험요인.
- 가장 높은 위험의 영향을 받는 개인.
- 평균 검사 재식별 위험도.
- 고유 레코드의 일부.
HIPAA identifiers (HIPAA 식별자)
미국 의료 보험 및 휴대성 및 책임에 관한 법률의 Safe Harbor 방법은 식별되지 않은 데이터 집합을 도출하기 위해 수정하거나 제거해야 하는 식별자 18개의 식별자를 지정합니다. 이러한 관점의 목적은 이러한 식별자를 탐지하는 것입니다.

참고 :이 방법은 최선을 다해 작동합니다. HIPAA 식별자가 감지되지 않는다고해서 HIPAA 식별자가 없다는 의미는 아닙니다. ARX는 정밀도보다 리콜을 선호하며 모든 유형의 HIPAA 식별자를 감지하는 방법을 구현하지 않습니다. HIPAA에서 지정한 다음 유형의 속성이 잠재적으로 감지 될 수 있습니다.
- Names(이름),
- Geographical subdivisions(지리적 세분화) : regions(지역), states(주), cities(도시),
- Dates(날짜),
- Phone numbers(전화번호),
- Fax numbers(팩스 번호),
- Electronic mail addresses(전자 메일 주소),
- Social Security numbers(사회 보장 번호),
- License plate numbers(번호판),
- Universal Resource Locators (URLs),
- Internet Protocol (IP) addresses.
메소드는 HIPAA 식별자에 대한 공통 레이블과 데이터 집합에 있는 속성의 레이블 사이의 편집 거리를 계산합니다. 또한 공통 패턴(예: 번호판 번호, ZIP 코드 및 날짜) 및 공통 인스턴스 값(예: 이름 및 성)에 대한 속성 값을 확인합니다.
Population uniqueness (인구 고유성)
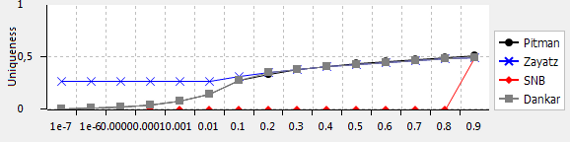
ARX는 표본의 모집단 고유값 수를 기반으로 재식별 위험 추정을 지원합니다. 모집단 고유값은 표본 내에서 고유하고 데이터가 표본이 된 기본 모집단 내에서 고유한 레코드입니다. 참고: 모든 표본 고유치가 모집단 고유값도 아닙니다. 모집단 표 형식으로 모집단에 대한 데이터가 ARX에 로드되지 않은 경우 통계적 모형을 사용하여 이 숫자를 추정할 수 있습니다. 모집단 모형은 표본 특성으로 모수화된 확률 분포를 사용하여 전체 모집단의 특성을 추정합니다. ARX는 호시노(핏맨), 자야츠, 첸, 맥널티(SNB)의 방법을 지원합니다.
모형에 따라 모집단 고유값 수에 대한 정확한 추정치가 다르게 반환될 수 있습니다. 경험에 비추어 볼 때 Pitman 모델은 10% 이하 분율의 표본 추출에 사용해야 합니다. 또한 ARX는 Dankar 등이 임상 데이터셋에 대해 제안하고 검증한 의사결정 규칙을 구현합니다. 자세한 내용은 여기에서 확인할 수 있습니다.
이 도구는 다른 표본 추출 분율을 가정하여 여러 가지 방법의 결과를 비교할 수 있는 뷰도 제공합니다.
통계적 모델을 사용하여 추정치를 계산하는 과정에서 ARX는 비선형 이바리산 방정식 시스템을 해결해야 합니다. ARX에서 사용하는 해결사는 설정 대화상자에서 구성할 수 있습니다. 여기서 총 반복 횟수, 시도당 반복 횟수, 필요한 정확도 등과 같은 옵션을 지정할 수 있습니다. 이러한 설정을 변경하면 결과의 정밀도와 결과를 얻는 데 필요한 시간에 영향을 미칠 수 있습니다.
참고: 모집단 고유성을 추정하는 방법은 데이터 집합이 모집단의 균일한 표본이라고 가정합니다. 그렇지 않을 경우 결과가 부정확할 수 있습니다.
Population settings (인구 설정)
데이터 집합의 모집단 고유값 수를 추정하는 방법을 사용하려면 데이터 집합이 샘플링된 모집단에 대한 일부 기본 데이터가 필요합니다. ARX는 구성 관점에서 다음 영역에서 선택할 수 있는 미국, 영국, 프랑스 또는 독일과 같은 모집단에 대한 기본 설정을 제공합니다.

기본 모집단은 예상 적수가 데이터를 추출한 것을 알 가능성이 높은 모집단과 일치해야 합니다. 필요한 데이터가 ARX에서 제공되지 않는 경우 수동으로 입력할 수도 있습니다.
참고: 모집단 고유성을 추정하는 방법은 데이터 집합이 모집단의 균일한 표본이라고 가정합니다. 그렇지 않을 경우 결과가 부정확할 수 있습니다.
레퍼런스
ARX
- Youtube : Data De-Identification with the ARX Data Anonymization Tool
- ARX : ARX 툴 사용법
- ARX - 프리젠테이션 자료
NIA한국정보화진흥원